
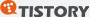


📋 이 글의 핵심 요약 (TL;DR)
· 가중치 그래프 : 간선에 비용·거리·시간 등 가중치가 할당된 그래프 (G = V, E, w)
· 표현 방법 : 인접 행렬(가중치 행렬로 확장) / 인접 리스트(노드별 연결 리스트)
· MST(최소비용 신장트리) : 모든 정점을 n-1개의 간선으로, 가중치 합이 최소가 되도록 연결
· 크루스칼(Kruskal) : 간선 중심 — 가중치 작은 간선부터 선택, 사이클 형성 시 제외
· 프림(Prim) : 정점 중심 — 하나의 정점에서 시작해 인접한 최소 가중치 정점을 단계적으로 확장
· 허프만(Huffman) : 데이터 압축 알고리즘 — 빈도 높은 문자 = 짧은 코드, 빈도 낮은 문자 = 긴 코드
01 가중치 그래프란?
💡 정의
가중치 그래프(Weighted Graph)란 간선(Edge)에 비용(cost), 가중치(weight), 또는 거리(length)가 할당된 그래프입니다. 단순히 정점 간 연결 여부만 나타내는 일반 그래프와 달리, 연결에 필요한 비용 정보까지 함께 표현합니다.
수학적으로는 G = (V, E, w) 로 표현하며, 각 요소의 의미는 다음과 같습니다.
| 기호 | 표현 | 의미 |
| V(G) | 정점(Vertex)들의 집합 | 그래프를 구성하는 모든 노드 |
| E(G) | 간선(Edge)들의 집합 | 정점 간 연결 관계 |
| w(e) | 간선 e의 가중치 | 강도, 비용, 거리, 시간 등의 값 |
✅ 실생활 활용 예시
· 컴퓨터 네트워크 : 인터넷 망에서 패킷을 가장 빠른 경로로 전송할 때
· 통신망 구축 : 광통신·전화망 등 통신망이 다를 때 가중치로 비용 차등 부여
· 도로 네비게이션 : 도시 간 거리·이동 시간을 간선의 가중치로 표현
· 배관·전기 회로 : 파이프나 전선의 길이를 최소화하는 경로 탐색
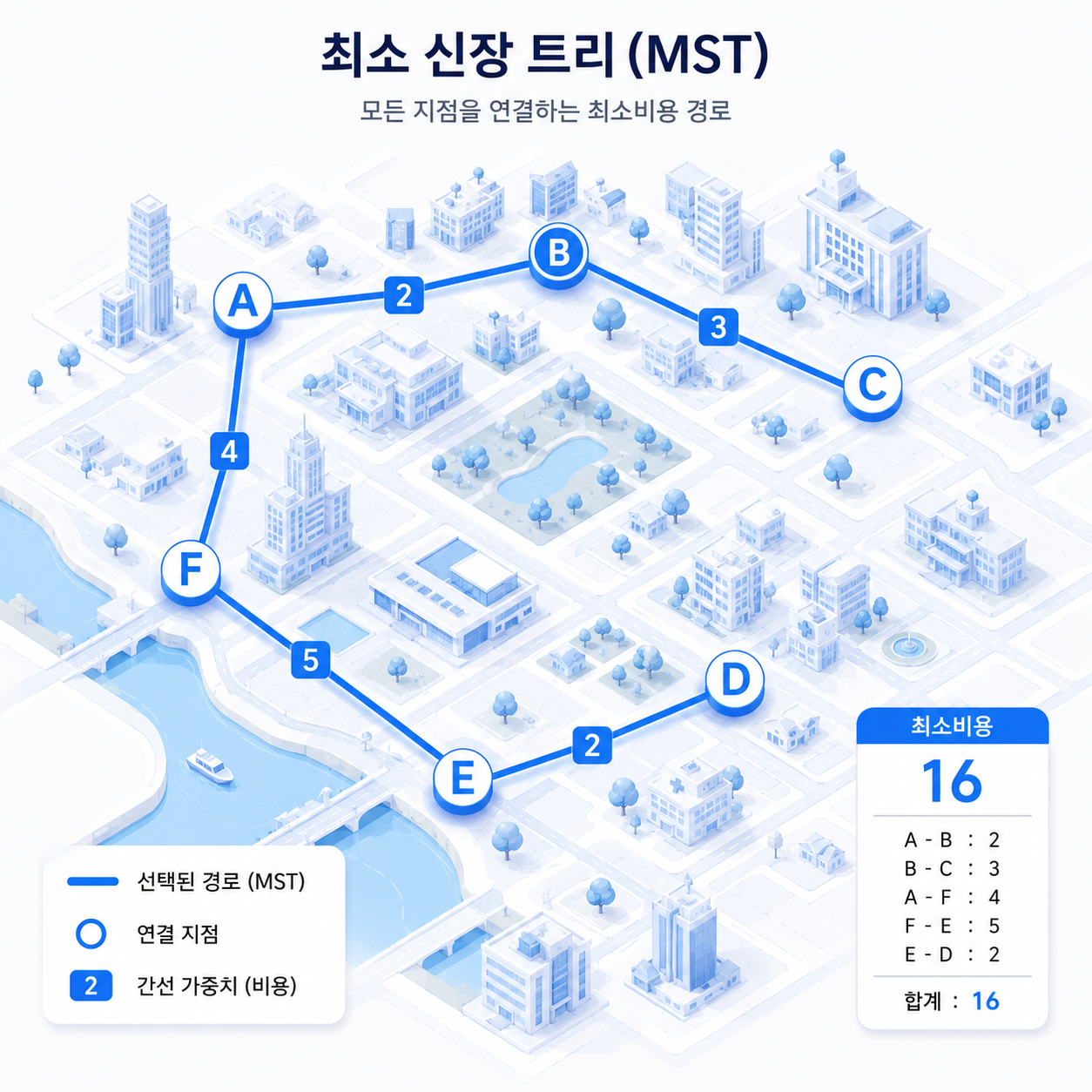
02 가중치 그래프의 표현 방법
가중치 그래프는 인접 행렬과 인접 리스트 두 가지 방식으로 표현할 수 있습니다.

| 📊 인접 행렬 (Adjacency Matrix) · 행렬의 각 셀에 0 또는 1 대신 가중치 값을 저장 · 자기 자신으로 가는 대각선만 0, 연결되지 않은 정점 간에는 ∞ (코드상 INT_MAX 등 큰 값) 기입 · 추가 메모리 없이 가중치 표현 가능 · n×n 행렬이므로 정점이 많을수록 메모리 낭비 발생 |
🔗 인접 리스트 (Adjacency List) · 각 정점마다 연결 리스트를 가짐 · 리스트의 각 노드에 (인접 정점, 가중치) 쌍 저장 · 같은 리스트 내 순서는 무관 · 간선 수가 적을 때(희소 그래프) 메모리 효율적 |
⚠️ 주의 — 가중치 그래프 인접 행렬에서 0의 의미
일반 그래프에서는 0이 '간선 없음'을 뜻하지만, 가중치 그래프에서 0은 '비용이 0인 간선이 실제로 존재'함을 의미할 수 있습니다. 연결되지 않은 정점 사이를 0으로 채우면 알고리즘이 "비용 0짜리 경로가 있다"고 잘못 해석하여 치명적인 버그가 발생합니다.
✔ 올바른 초기화 : 자기 자신(대각선) = 0 / 연결 없는 정점 간 = ∞ (소스코드에서는 INT_MAX 등 충분히 큰 값)
03 최소비용 신장트리 (MST)
📌 신장트리(Spanning Tree)란?
그래프 G의 모든 정점을 포함하면서, 사이클이 없는 트리입니다. 하나의 그래프에서 다양한 형태의 신장트리가 만들어질 수 있습니다.
💡 최소비용 신장트리 (MST: Minimum Spanning Tree)
여러 신장트리 중 간선 가중치의 합이 가장 작은 신장트리입니다.
통신망·도로망·유통망처럼 모든 지점을 가장 저렴하게 연결해야 할 때 사용합니다.
❌ MST의 필수 조건 3가지
① 간선 가중치의 합이 최소여야 한다
② 반드시 n-1개의 간선만 사용해야 한다 (정점 수가 n일 때)
③ 사이클(순환)이 포함되면 안 된다
MST를 구하는 대표 알고리즘은 크루스칼(Kruskal)과 프림(Prim) 두 가지입니다.
04 크루스칼(Kruskal) 알고리즘
💡 핵심 개념 — 간선(Edge) 중심 접근
탐욕 알고리즘(Greedy Algorithm) 기반으로, 매 단계에서 "지금 당장 가장 싼" 간선을 선택합니다. 사이클이 생기면 해당 간선은 버리고, n-1개의 간선이 연결될 때까지 반복합니다.
🔢 크루스칼 알고리즘 수행 단계
| ① 간선 정렬 모든 간선을 가중치 오름차순 정렬 |
→ | ② 간선 선택 가중치 가장 작은 간선 차례로 선택 |
→ | ③ 사이클 검사 사이클 형성 시 해당 간선 제외 |
→ | ④ 종료 조건 n-1개 간선 연결 완료 시 종료 |

✅ 크루스칼 알고리즘 규칙 정리
① 가중치가 가장 작은 간선을 차례로 선택
② 가중치가 같은 간선은 모두 선택
③ 선택된 간선에 의해 사이클이 형성되면 선택하지 않음
④ 정점 수가 n개일 때, n-1개의 간선이 연결되면 종료
크루스칼 알고리즘 — 의사코드(Pseudocode)
MST-Kruskal(G, w) {
// 1. 모든 간선을 가중치 오름차순으로 정렬
edges = sortByWeight(G.E)
result = [ ] // MST에 포함될 간선 집합
for each edge (u, v) in edges:
if (u, v) does not form a cycle: // → Union-Find로 판별
result.add(u, v)
if result.size == n-1: break
}
📖 C언어 구현 팁 — Union-Find(서로소 집합)
의사코드의 "does not form a cycle" 조건은 실제 C언어 구현에서 Union-Find(유니온-파인드) 알고리즘으로 처리합니다. 각 정점이 속한 집합의 '대표(루트)'를 추적하는 트리 구조로, 두 정점의 루트가 같으면 같은 집합(= 연결하면 사이클 발생), 다르면 다른 집합(= 안전하게 간선 추가)임을 O(α(n)) 거의 상수 시간에 판별합니다.
· find(x) : 정점 x가 속한 집합의 루트를 반환
· union(x, y) : 두 집합을 하나로 합침 — 간선 (x, y) 선택 시 호출
05 프림(Prim) 알고리즘
💡 핵심 개념 — 정점(Vertex) 중심 접근
하나의 시작 정점에서 출발하여 트리를 단계적으로 넓혀 나갑니다. 현재 트리에 인접한 정점들 중 가중치가 가장 작은 간선으로 연결된 정점을 순서대로 추가합니다.
🔢 프림 알고리즘 수행 단계
| ① 시작 정점 선택 임의의 노드 하나를 선택 |
→ | ② 최소 간선 확장 연결된 노드들 중 최소 가중치 간선 선택 |
→ | ③ 반복 / 종료 사이클 제외하며 n-1개 간선까지 반복 |

✅ 프림 알고리즘 규칙 정리
① 그래프에서 임의의 노드 하나를 선택하여 시작
② 선택된 노드들과 연결된 모든 간선 중 가중치가 가장 작은 간선 선택
③ 가중치가 같은 간선은 임의로 하나를 선택
④ 순환(사이클)이 형성되는 간선은 선택하지 않음
⑤ n개 정점이 있을 때, n-1개의 간선이 연결될 때까지 ②~④ 반복
| 🔵 크루스칼(Kruskal) · 간선 중심 (전체 간선 정렬 후 선택) · 간선이 적은 희소 그래프(Sparse Graph)에 유리 · Union-Find 자료구조로 사이클 탐지 |
🟠 프림(Prim) · 정점 중심 (하나의 점에서 확장) · 간선이 많은 밀집 그래프(Dense Graph)에 유리 · 우선순위 큐(Priority Queue)로 구현 |
⏱️ 시간 복잡도(Time Complexity) 비교
| 알고리즘 | 시간 복잡도 | 지배 요인 | 유리한 경우 |
| 크루스칼 | O(E log E) | 간선 정렬 | 간선 수 E가 적은 희소 그래프 (E ≪ V²) |
| 프림 (이진 힙) |
O(E log V) | 우선순위 큐 | 간선 수 E가 많은 밀집 그래프 (E ≈ V²) |
| 프림 (인접 행렬) |
O(V²) | 정점 순회 | 구현이 단순한 밀집 그래프 (학습/입문 단계) |
06 허프만(Huffman) 알고리즘
지금까지 가중치를 간선(Edge)에 적용하여 최적 경로를 찾는 크루스칼·프림을 살펴봤습니다. 이번에는 가중치 개념을 노드(문자의 빈도수)에 적용하여 데이터를 최적으로 압축하는 또 다른 탐욕(Greedy) 알고리즘인 이진 트리 기반의 허프만 코드를 함께 살펴보겠습니다.
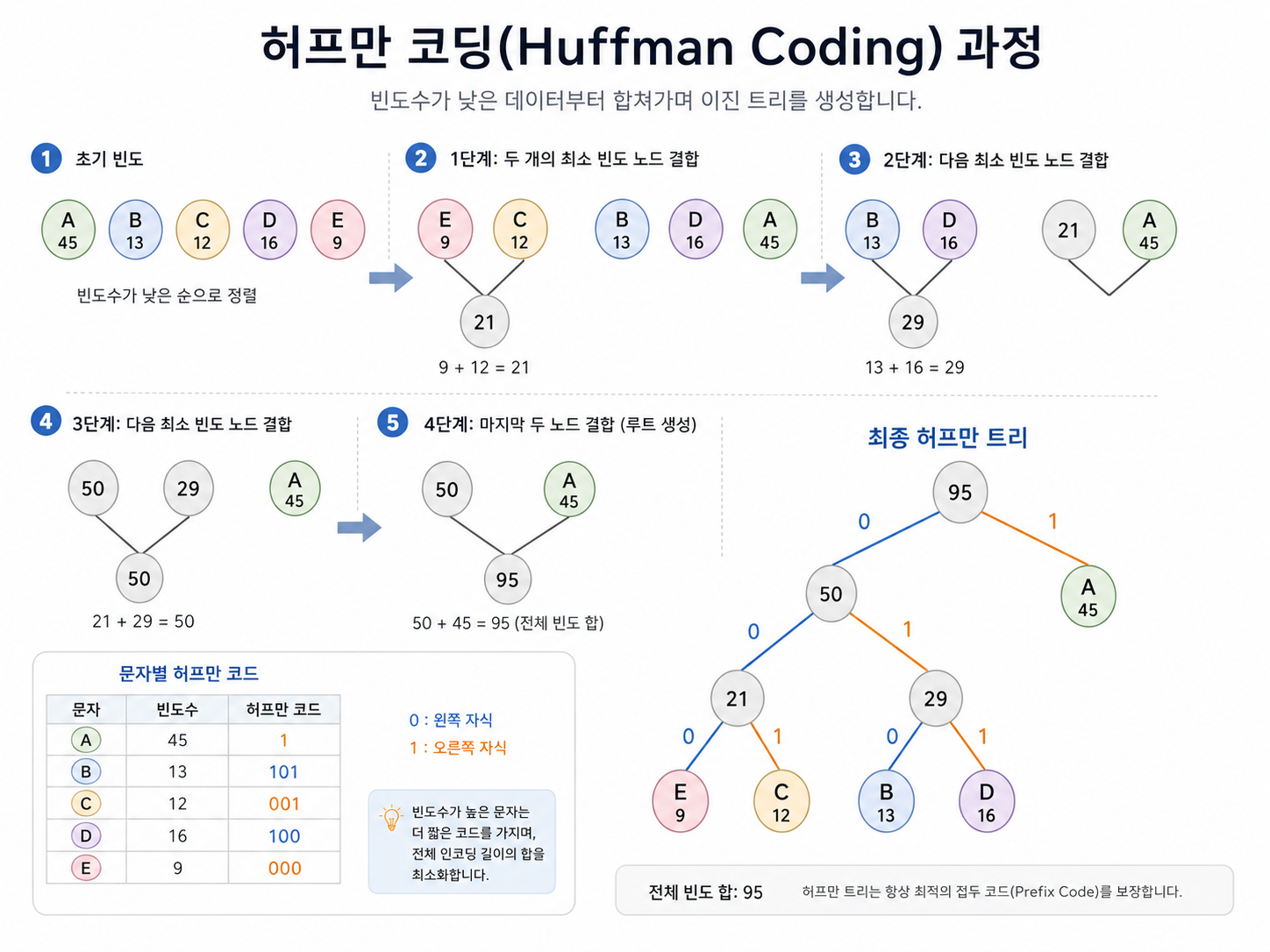
💡 허프만 코드(Huffman Code)란?
데이터 압축에 사용되는 알고리즘으로, 문자의 발생 빈도(frequency)를 가중치로 활용합니다.
· 발생 빈도가 높은 문자 → 짧은 비트 코드 할당
· 발생 빈도가 낮은 문자 → 긴 비트 코드 할당
→ 전체 데이터 크기를 최소화하는 효율적인 압축 방식
🔢 허프만 알고리즘 수행 단계
| 단계 | 수행 내용 |
| ① | 발생 빈도가 가장 낮은 두 문자를 선택하여 이진 트리 생성 |
| ② | 왼쪽 노드에 빈도 낮은 문자, 오른쪽 노드에 빈도 높은 문자 배치 (빈도가 같으면 사전 순서상 앞에 오는 문자를 왼쪽에 배치) |
| ③ | 두 문자의 빈도 합을 부모 노드 값으로 설정 |
| ④ | 모든 문자가 하나의 이진 트리로 묶일 때까지 ①~③ 반복 |
| ⑤ | 완성된 트리의 왼쪽 간선 = 0, 오른쪽 간선 = 1 부여 → 루트부터 각 문자까지의 비트열이 해당 문자의 코드 |
📖 심화 — 허프만 코드가 왜 효율적인가?
고정 길이 코드는 모든 문자를 동일한 비트 수(예: ASCII 8비트)로 표현합니다. 허프만 코드는 자주 쓰이는 문자에 2~3비트를, 드물게 쓰이는 문자에 6~8비트를 부여하는 가변 길이 코드입니다. 영어 텍스트 기준으로 평균 20~40%의 압축률을 달성할 수 있으며, ZIP·JPEG·MP3 등 다양한 압축 포맷의 기반 기술로 활용됩니다.
📌 핵심 정리
· 가중치 그래프 : G = (V, E, w) — 간선에 비용·거리 등 가중치를 부여한 그래프
· 인접 행렬 주의 : 연결 없는 정점 간 = 0이 아닌 ∞(INT_MAX) 로 초기화해야 오류 방지
· MST 조건 : ① 가중치 합 최소 ② n-1개 간선만 사용 ③ 사이클 없음
· 크루스칼(Kruskal) : 간선 정렬 → 최소 간선 선택(Union-Find로 사이클 판별) → O(E log E)
· 프림(Prim) : 임의 정점 시작 → 인접 최소 간선으로 트리 확장 → O(E log V) / O(V²)
· 허프만(Huffman) : 빈도 낮은 문자부터 이진 트리 구성 → 좌=0, 우=1 → 가변 길이 코드
태그 : 가중치 그래프란 최소비용 신장트리 MST 크루스칼 알고리즘 설명 프림 알고리즘 차이 허프만 코드란 자료구조 그래프 정리 인접 행렬 인접 리스트 차이 신장트리 사이클 조건 데이터 압축 알고리즘 C언어 자료구조 12강
'학과 수업 노트 > 자료구조' 카테고리의 다른 글
| 13. 정렬 (2) - 선택 정렬, 셀 정렬, 기수 정렬, 힙 정렬, 탐색 (0) | 2026.06.06 |
|---|---|
| 12. 정렬(1) - 개념, 버블정렬, 삽입정렬, 퀵정렬, 병합 정렬 (0) | 2026.05.30 |
| 10. 그래프 (0) | 2026.05.19 |
| 9. 이진 탐색 트리 (0) | 2026.05.09 |
| 8. 트리 (0) | 2026.05.03 |